Всеслав Соленик, 11/12/20
Есть известная парадигма “люди – процессы – технологии", из этих слагаемых состоит любой SOC: нужно нанять, обучить людей, построить и организовать процесс их работы по выявлению и обработке инцидентов, а затем автоматизировать процессы с помощью определенных технологических платформ. Но нельзя упускать еще один, не менее важный элемент: любой SOC строится вокруг данных. SOC, как и любая организационно-технологическая сущность, не может существовать без данных и знаний. Поэтому рассмотрим различные типы данных, а также методы их обработки, которые необходимы в SOC.
Автор: Всеслав Соленик, директор центра экспертизы R-Vision
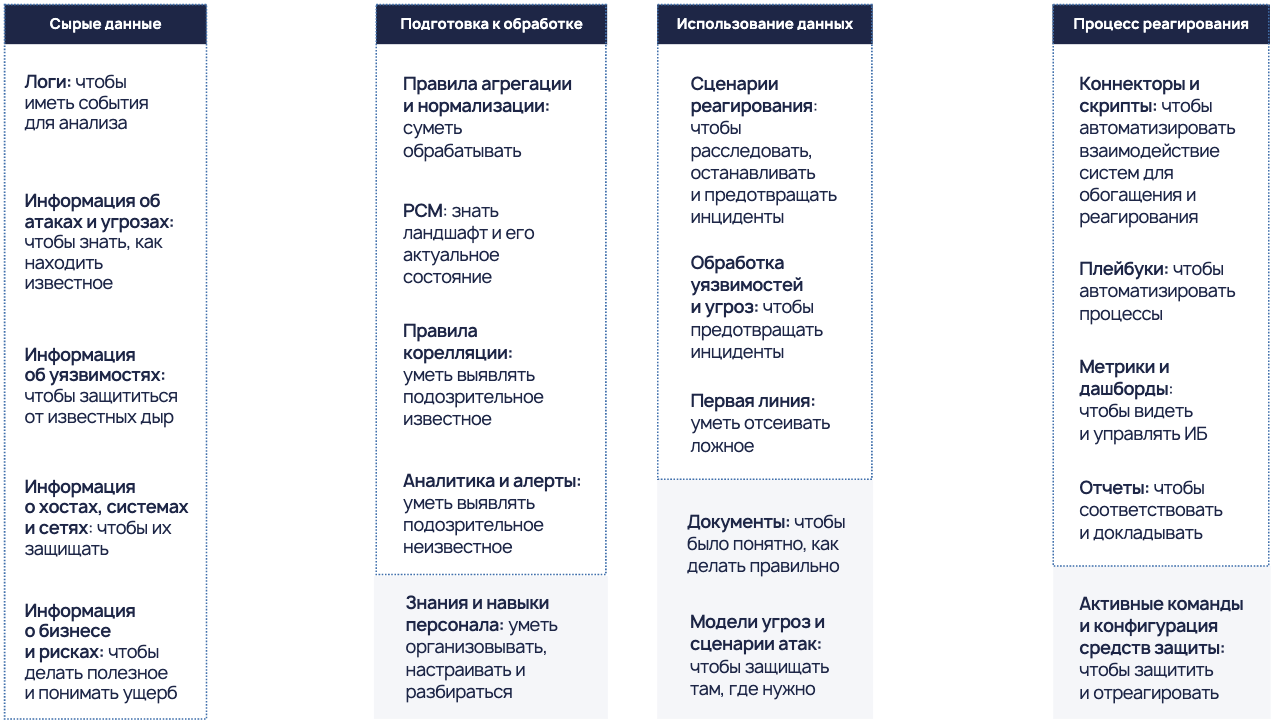
Сырые данные
Первое, что мы должны направить в "черный ящик" SOC, – это сырые данные нескольких типов.
- Логи. Реагирование на инциденты начинается с умения их выявлять. А любое выявление инцидентов строится на по возможности максимально широкой фиксации и сборе происходящих в организации и ее системах событий и поиске в них маркеров того, что произошел инцидент. Поэтому важно организовать поступление в SOC логов и событий, с использованием которых будет осуществляться поиск инцидентов. По сути, речь идет о стандартном лог-менеджменте: события гарантированно собираются с ИТ-инфраструктуры, из бизнес-систем, с других каналов, по которым может проходить информация, и анализируются.
- Информация об известных атаках и угрозах. Она нужна для того, чтобы выявлять эти атаки в общем потоке событий по паттернам. Уточним, что информация, приходящая из внешних источников, помогает находить только известные атаки и угрозы. Как правило, на сегодняшний день, если где-то кто-то столкнулся с некой угрозой, информация об индикаторах атаки, включая вирусные сигнатуры, становится доступной через различные CERT, обновления баз сигнатур или фиды. Сигнатуры и индикаторы компрометации в рамках Threat Intelligence (TI) – это второй поток данных, приходящих в SOC.
- Информация об уязвимостях. Данные об уязвимостях поступают из нескольких источников и, несмотря на видимую структурированность, для SOC они тоже являются сырыми, поскольку:
- они не учитывают контекст защищаемой организации;
- в каждом источнике данные имеют свою нотацию, формат, полноту и пр.
- Информация о защищаемых хостах, системах и сетях. Невозможно реагировать на инциденты, не понимая контекст информационных активов организации, с которыми инцидент происходит. Эти данные тоже являются для SOC сырыми, потому что большей частью поступают от внешних инфраструктурных и ИТ подразделений, из различных CMDB-систем, и, как правило, являются разрозненными, ненормализоваными и неполными. Они важны для получения полного контекста и ландшафта защищаемой организации и используются при реагировании на конкретный инцидент.
- Информация о бизнесе и рисках. Часто этот поток данных в SOC вообще не анализируется, но это большая ошибка, поскольку SOC строится именно для того, чтобы приносить пользу бизнесу. Поэтому при реагировании на инциденты обязательно нужно иметь информацию о том, какие бизнес-процессы и системы функционируют в организации. Без этого невозможно ни приоритизировать инциденты, ни взаимодействовать при реагировании с бизнес-подразделениями – внутренними заказчиками всего сервиса информационной безопасности.
Необходимо также проводить анализ рисков, поскольку он дает понимание, какие инциденты могут привести к большему ущербу, а какие к меньшему. Зная это, можно расставлять приоритеты и планировать сроки для реагирования, чтобы не нанести активам недопустимый ущерб. Отсюда, по сути, вытекает SLA для обработки инцидентов – неотъемлемая часть процессов SOC. Сбор и ведение актуальной информации о бизнес-процессах, системах и рисках, включая процессы их оценки и обработки, удобно вести в системе класса SGRC.
Обработка данных
Когда в SOC заведены все необходимые потоки данных, необходимо провести их обработку. Это движение от сырых данных к экспертизе, к знаниям, которые важно создать и накопить в SOC. Разберем составляющие элементы обработки данных.
- Правила агрегации и нормализации. Данные приходят в SOC разрозненными из многочисленных источников, и необходимо выработать и обязательно апробировать правила агрегации и актуализации, чтобы сделать системной последующую работу с ними. Данные, поступающие в хаотическом виде и порядке, невозможно сделать полезными, их нужно нормализовать. Поэтому необходимо создать правила агрегации и нормализации – фундамент для накопления знаний и практик в SOC.
- Ресурсно-сервисная модель (РСМ). Она строится на основе информации о бизнесе, рисках, хостах, системах и сетях – по сути, на традиционных сведениях об инвентаризации, поступающих в SOC. Необходимо реализовать полноценную модель взаимосвязей между всеми активами организации, чтобы в случае, если с любым из активов произошел инцидент, четко понимать ландшафт этого инцидента. Важно построить процесс так, чтобы в SOC была актуальная информация о защищаемых активах. Построенная РСМ также является знанием SOC, и ее наличие позволяет в случае инцидента начать реагирование максимально оперативно, не тратя времени на сбор информации. К слову, реализация полноценной РСМ невозможна без использования платформы для ее сбора и актуализации, например SGRC или IRP.
- Правила корреляции. Эта экспертиза должна быть выработана в SOC, и она заключается в документированных знаниях о том, какое сочетание различных событий и их атрибутов свидетельствует о потенциальном инциденте. Соответствующие правила корреляции создаются и используются для выявления подозрений на инцидент. При этом с помощью данных правил можно выявить только известные или проанализированные на этапе подготовки инциденты, а инциденты, возникновение которых не предполагалось и для которых сценарии не были проработаны заранее, мы так не увидим. Эти правила важно поддерживать в актуальном состоянии, методологически развивать подходы к ним, постоянно дорабатывать их и адаптировать под изменяющиеся условия.
- И наконец, аналитика и алерты. Это результат работы аналитиков, работающих в SOC и непосредственно расследующих инциденты. Она накапливается у них в виде разнообразных практик, и хорошо, если они документированы. Есть и второй компонент – системы класса UEBA или платформы кибераналитики, откуда алерты также могут поступать в SOC в случае обнаружения девиантного поведения отслеживаемых активов.
Отличие от правил корреляции здесь в том, что, получая алерты о какой-либо аномалии, нельзя быть полностью уверенным, что это действительно маркеры инцидента. Но они определенно свидетельствуют о чем-то подозрительном. Выявление аномалий, анализ и организация обмена алертами – неотъемлемая часть подготовки к реагированию на неизвестные инциденты, не предусмотренные правилами корреляции.
Использование данных
После того как сырые данные заведены в SOC, подготовлена экспертиза, делающая данные полезными, можно начинать их использование. Данные нормализованы, вокруг них есть ландшафт, сформировано понимание того, какое сочетание событий и маркеров в этих данных сигнализирует об инциденте. И когда инцидент выявлен, нужно начать на него реагировать, для чего используется набор процессов и методик.
- Сценарии реагирования. В SOC должна быть создана и накоплена экспертиза по конкретным шагам расследования инцидента каждого типа, она может поступить из внешних источников (например, консалтинга) либо формироваться своими силами. Эта экспертиза в виде пошаговой инструкции и есть сценарий реагирования. Он может быть написан на бумаге, может существовать только в голове у аналитиков SOC или может присутствовать в автоматизированном виде, но сами знания о том, как реагировать на конкретные инциденты, должны быть выработаны до того, как наступил инцидент. Как правило, для этого методологически прорабатываются сценарии атак, моделируются угрозы и нарушители, чтобы в дальнейшем уже смотреть, где, каким образом мы выявляем эти атаки по killchain, реагируем и пр.
- Процесс обработки уязвимостей и угроз. Информация об уязвимостях пришла в SOC в виде сырых данных из NVD, сканеров уязвимостей или от пентестеров. SOC должен построить этот процесс как часть своей экспертизы. Аналогично он должен обработать, обогатить и распространить на средства защиты индикаторы компрометации из внешних фидов, чтобы выявлять их в защищаемой инфраструктуре и оперативно реагировать. Результат – понимание, что делать с данными об уязвимостях и угрозах и четкий процесс применения этих данных, снижающий риск инцидентов и повышающий эффективность работы SOC. Для автоматизации этих процессов используются системы класса Vulnerability Management (в том числе как часть SGRC/IRP) и Threat Intelligence Platform.
- Отсеивание ложных срабатываний (False Positive). Это крайне важный тип знаний для аналитиков, ведь ложные срабатывания – бич любого SOC. Как бы качественно мы ни старались обрабатывать сырые данные, всегда будет присутствовать некоторый поток ложных срабатываний. Если не научиться их выявлять, группировать и отсеивать, то работа SOC будет быстро парализована: все будут заняты обработкой тысяч неактуальных инцидентов, а реальные инциденты останутся без внимания.
Автоматизация
После того как данные собраны, обработаны и начато их использование для выявления инцидентов и реагирования на них, остался последний шаг – непосредственная автоматизация построенных процессов и обработки подтвержденных инцидентов. В этом случае в игру вступают два типа знаний и экспертизы: коннекторы и скрипты, а также плейбуки и настройки систем автоматизации.
- Коннекторы и скрипты. Это программные объекты, которые помогают автоматизировать взаимодействия между различными системами и участниками процесса для быстрого и качественного обогащения данных и, возможно, активного автоматического реагирования на средствах защиты. Необходимо написать соответствующее количество коннекторов и скриптов, которые оптимизируют внутреннее взаимодействие в SOC и сделают расследование максимально быстрым и эффективным, а значит ущерб – минимальным.
- Плейбуки. Это те самые сценарии реагирования, которые реализованы в виде настроенных автоматизированных процессов и в которых используются скрипты и коннекторы. Если сценарий реагирования – это логическая сущность, то плейбук – это уже программная сущность, реализованная в системе класса SOAR (или IRP).
Метрики и дашборды
После того, как настроены процессы сбора данных, выявления инцидентов, реагирования и их автоматизация, важно не забыть, что обязательной частью экспертизы SOC являются качественные метрики, отчеты и визуальные панели (дашборды), придумать которые не так уж просто. Как правило, это результат хорошего консалтинга: как емко отслеживать наиболее важные результаты работы SOC, видеть его операционную работу и управлять качеством выявления и реагирования на инциденты. Это же касается и разнообразной отчетности, которая необходима в SOC для соответствия законодательным требованиям, если, например, это SOC, в котором обрабатываются инциденты КИИ, или для соответствия большому количеству различных аудиторских и прочих требований. Соответствие требованиям законодательства может обеспечиваться, например, с помощью системы класса SGRC. Кстати, отчетность нужна и для того, чтобы делать процессы SOC и его работу прозрачной для руководства, поскольку оно, как правило, смотрит именно на отчеты и графики чтобы оценить, насколько качественно построен SOC, насколько хорошо он выполняет свою работу.
В качестве заключения
При построении SOC не стоит забывать и об общих знаниях и процессах организации, в том числе смежных. Есть верхнеуровневые регламенты и системы компании, которые распространяются на SOC, например управление знаниями и системы класса Wiki. Они тоже должны фигурировать в SOC и документироваться.
Актуален и вопрос знаний по настройке систем автоматизации ИБ и СЗИ, которые помогают нам реагировать на инциденты и обеспечивают информационную безопасность на техническом уровне. SOC необходим набор данных и набор документированных знаний по тому, как должны быть сконфигурированы средства автоматизации и защиты и как они работают, ведь в случае инцидента времени на поиск нужной информации не остается.
Таким образом, на основе экспертизы с наших проектов мы составили достаточно объемную картинку того, какие данные и знания должны быть созданы, агрегированы, аккумулированы в SOC, чтобы та самая триада "люди – процессы – технологии" обеспечила его эффективную работу.