






Александр Бердюгин, 21/10/22
Авторы книги “Неуязвимость. Отчего системы дают сбой и как с этим бороться” Андраш Тилчик и Крис Клирфилд указывают на сложность систем как на одну из причин возникновения аварий. Речь идет о масштабных системах, сложность которых неизбежно возрастает по мере перехода большинства компаний на микросервисы и прочие распределенные технологии. Избавиться от нее невозможно, но при помощи хаос-инжиниринга (Chaos Engineering) можно обнаружить уязвимости и предотвратить сбои до того, как они окажут воздействие на пользователей.
Автор: Александр Бердюгин, младший научный сотрудник департамента информационной безопасности Финансового университета при Правительстве РФ
Знакомьтесь: хаос-инжиниринг
Представим, что у нас имеется небольшой абстрактный сервис (см. рис. 1) с рядом зависимостей. Для большинства проектов это типичный случай, особенно для микросервисной экосистемы. Количество зависимостей не имеет принципиального значения.
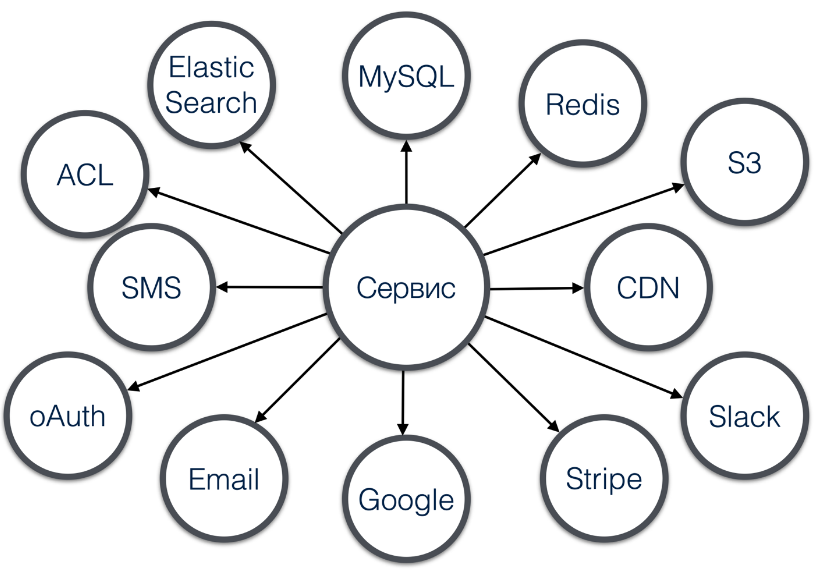
Рис. 1
Предположим, что сервис готов: приложение подготовлено к релизу, система достаточно стабильна, проект устойчив к проблемам – пришло время развернуть его на новой машине, то есть задеплоить, для непосредственного производства. Но прежде чем запустить сервис в широкое пользование, необходимо учесть распространенные проблемы.
Не существует сервисов, у которых не возникает сбоев – они не просто возможны, а обязательно будут. Поэтому проект должен быть хорошо протестирован. Конечно, 100%-ная проверка перед запуском невозможна, но обязательно нужно тестировать следующие системы и структуры, наиболее подверженные уязвимостям и рискам:
- внешние сервисы, которые живут своей жизнью и развиваются по собственному таймлайну: могут внезапно перестать работать, у них может поменяться время ответа, формат ответа и т.д. Код таких сервисов лучше заранее сделать более гибким;
- сеть, диски, базы данных;
- инфраструктура ИТ (организационные структуры, а также подсистемы, обеспечивающие функционирование, развитие киберпространства системы и средств информационного взаимодействия);
- человеческие ресурсы (так называемый человеческий фактор). Необходима постоянная работа с сотрудниками компании на предмет ИТ- и ИБ-грамотности, ведь кто угодно может допустить логическую ошибку, из-за которой что-то начнет работать не так.
Перечисленные пункты представляют далеко не весь список рисков, которые сложно покрыть юнит- или интеграционным тестированием, – это только верхушка айсберга. Например, распределенные DDoS-атаки, происходящие с завидной регулярностью, относятся к тем вариантам рисков, которые невозможно предсказать с помощью тестирований.
Что же такое контролируемый хаос?
Тут на сцену выходит хаос-инжиниринг – дисциплина, которая помогает подготовить приложение к тому, что реализация киберрисков возможна всегда.
В соответствии с сутью хаос-инжиринга перед нами встает задача построить приложение так, чтобы оно было готово к проблемам. Мы не будем маскировать проблемы тестами, а подготовим проект, устойчивый к любым сбоям, которые обязательно случатся.
Хаос-инжиниринг представляет собой набор экспериментов над системой/проектом/сервисом, включающий в себя в том числе контролируемые сбои, для выявления потенциальных проблем, которые могут возникнуть в продакшн-окружении [1]. Первоначально понятие и дисциплину создал Грегори С. Орзелл (Gregory S. Orzell) для тестирования миграции из центра обработки данных компании Netflix в облачные технологии в 2011 г. Netflix – достаточно крупная компания, можно себе представить, чего им стоило перенести весь огромный объем своих компонентов в облако.
В Сети можно найти принадлежащие Грегори С. Орзеллу патенты на некоторые технологии, применяющиеся в хаос-инжиниринге, – настолько серьезно он подошел к этому. В процессе создания дисциплины он пытался ответить на вопросы, как перебраться в облако, как быть готовым к отказам в работе микросервисов, как подготовить всю систему к сбоям.
Netflix разработала множество методов, которые вводят риски и проблемы в проект. Эти риски могут быть связаны с дисковой подсистемой, с сетью, с дата-центрами – с чем угодно.
Этапы проведения хаос-инжиниринга
На первом этапе нужно понять, что такое устойчивое состояние в рассматриваемой системе (метрики, показатели). Какие метрики снимать – никакого золотого правила нет, но они должны однозначно заявлять, что система (приложение) находится в стабильном устойчивом состоянии, и быть зафиксированными. Стоит отметить преимущество найма аналитиков для подобной работы, ведь главная цель анализа данных с различных дашбордов – получить инсайты, которые помогут принять верные решения.
На втором этапе осуществляется выбор контрольной и экспериментальной группы. Не нужно внедрять хаос во всю систему (приложение) целиком, учитывая тот факт, что хаос-инжиниринг применяется в продакшн-окружении.
На третьем этапе нужно ввести некоторые предположения о состоянии групп. Ближайшая аналогия – структурированный метод анализа сценариев "что, если?" (SWIFT – Structured What-If Technique), представляющий собой систематизированное исследование сценариев, основанное на командной работе. Для анализа используются фразы-подсказки "что, если", которые позволяют установить опасные ситуации и разработать сценарии развития и предотвращения кризисных ситуаций. Например: что, если сервис/сервер перестанет работать? что, если террористы взломают крупнейшие финансовые организации мира?
Одним из самых интересных этапов является четвертый этап проведения хаос-инжиниринга. Ему посвящено введение переменных, отражающих реальные события: нужно внедрить предположенные ранее гипотетические проблемы в выбранную экспериментальную группу.
На пятом этапе происходит попытка опровергнуть предположения. Хаос-инженеру интересно опровержение предположений, сделанных на третьем этапе, он должен усомниться в том, что приложение устойчиво к проблемам.
Прохождение этих этапов необходимо, чтобы исправить вероятные проблемы в экспериментальной группе и подготовить систему к их реализации в действительности (см. рис. 2).
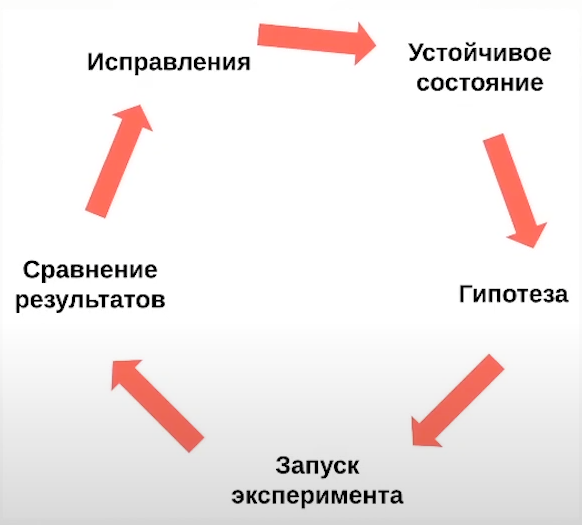
Рис. 2. Этапы проведения хаос-инжиниринга
Дисциплина хаос-инжиниринга подразумевает, что он будет проводиться на постоянной основе. В одних компаниях эти эксперименты проводятся раз в месяц, в других компаниях – раз в неделю, в третьих компаниях – перед релизом, который бывает нечасто или один раз в квартал. В крупных компаниях есть целые подразделения, которые занимаются исключительно поиском тех погрешностей, к которым приложения еще не готовы.
Автоматизация хаос-инжиниринга
Предшественником хаос-инжиниринга является антихрупкость (англ. Antifragility) – понятие, введенное профессором, экономистом и трейдером Нассимом Николасом Талебом (Nassim Nicholas Taleb) в книге "Антихрупкость. Как извлечь выгоду из хаоса". Понятие используется преимущественно применительно к живым организмам (в экологии, физиологии, психологии и т.д.) и обозначает способность системы улучшать свои показатели и процветать в ответ на хаос, сбои, риски и стресс.
Какие решения разработаны для проведения хаос-инжиниринга? Такие инструменты есть у компании Netflix, поскольку они начали первыми этим заниматься. Это Chaos Monkey и The Simian Army, а также Chaos Engine, Gremlin, Fault Injection Queries (Amazon Aurora), Azure Fault Analysis Service и др.
На сегодняшний день популярны программные SAS-решения, которые охватывают все этапы работы с информацией (сбор, изменение, управление и извлечение данных из различных источников), а также выполняют их статистический анализ.
Netflix использует собственный пакет приложений Simian Army, который тестирует стабильность его сети различным образом и имеет более десятка стрессоров. Chaos Monkey является составной частью пакета Simian Army, реализует стратегию кибербезопасности в технологиях облачных вычислений, которая основана на хаос-инжиниринге [2].
Хаос-инжиниринг в облаке
Большинство инцидентов информационной безопасности в облачной инфраструктуре за последние годы вызваны человеческими ошибками и неправильно сконфигурированными ресурсами. Для их преодоления необходимы новые модели безопасности. Эти модели должны использовать упреждающие методы, быть адаптированы к запросам клиента, непрерывны, не ориентированы на традиционные парадигмы кибербезопасности, такие как обнаружение вторжений.
Хаос-инжиниринг – это дисциплина, которая делает упор на преднамеренное внедрение ошибок в программные системы, чтобы минимизировать время простоя и вероятность реализации инцидентов при одновременном повышении отказоустойчивости. Основной мотивацией для такого подхода является преодоление неопределенностей, распространенных в распределенных системах, например в облачной инфраструктуре. Компании, применяющие принципы хаотической инженерии, например Netflix, используют отказоустойчивые среды в общедоступных облаках. Аналогичные вопросы еще предстоит решить в сфере облачной безопасности, при этом количество нарушений безопасности растет. Интересно, что значительная их часть вызвана человеческими ошибками, например неправильно настроенными политиками контроля доступа (Access Control Policies – ACP) и предоставлением чрезмерных привилегий некоторым пользователям. Альянс облачной безопасности (The Cloud Security Alliance – CSA) утверждает, что наиболее серьезные проблемы облачной безопасности в 2019 г. – утечка данных, а также неправильная настройка и неадекватный контроль изменений. Этот факт отражен в отчете Ponemon Institute о нарушениях данных за 2019 г. [3], где утверждается, что 49% нарушений вызваны системными сбоями и человеческими ошибками.
- Production-окружение – это окружение развертывания программного обеспечения, то есть рабочее, так называемое боевое, окружение, в котором производится работа с реальными клиентами и актуальными данными.
- Хаос-инжиниринг: специальная точка добавления багов. URL: https://www.securitylab.ru/blog/company/PandaSecurityRus/343387.php (дата обращения: 29.07.2022).
- IBM Security. 2019 cost of a data breach report. URL: https://www.ibm.com/downloads/cas/RDEQK07R (дата обращения: 30.07.2022).








