






Алексей Лукацкий, 27/05/20
В конце прошлого года в России прошел SOC Forum, собравший на своей площадке более 2 тыс. человек, интересующихся темой мониторинга информационной безопасности. Во время подготовки к этому мероприятию на сайте форума был запущен опрос среди владельцев центров мониторинга ИБ (Security Operations Center, SOC), им задали более тридцати вопросов, в том числе и об оценке своей эффективности.
Автор: Алексей Лукацкий, консультант по информационной безопасности
Если мы посмотрим на результаты этого опроса, то увидим, что число SOC, использующих метрики для измерения своей эффективности, очень невелико: ее измеряют всего 15% SOC, работающих в России. В мире ситуация тоже не идеальна: далеко не все центры мониторинга занимаются оценкой эффективности своей деятельности. Хотя надо признать, что уровень зрелости зарубежных SOC выше, чем у нас, как и число тех, кто измеряет себя и применяет для этого различные метрики. Какие же метрики можно использовать для того, чтобы показать себе и руководству, что инвестиции, сделанные в SOC, сделаны не зря? Давайте попробуем посмотреть на распространенные примеры.
Число инцидентов
Число инцидентов -- самая простая метрика. Ее легко посчитать и показать динамику изменения. Но за ее простотой скрывается и ряд сложностей. Если в прошлом месяце у меня был 21 инцидент, а в этом -- 33, то с чем связан такой 50%-ный рост? Нас стали больше атаковать? Или мы покрыли мониторингом большее число систем? Или мы улучшили качество мониторинга? А может, мы изменили понятие инцидента или провели обучение аналитиков SOC? Причин такого явления может быть множество, и без их разбора использовать такую метрику нельзя, так как мы можем сделать неверные выводы, которые приведут нас к неверным управленческим решениям.
Время
По названным выше причинам измерение числа инцидентов -- это не единственная метрика, которая должна оцениваться SOC. Ее необходимо всегда сопровождать вторым значимым показателем. Это время! Это критический фактор, который очень важен при оценке того, насколько эффективно работают специалисты, технологии или процессы SOC. Чем быстрее мы обнаруживаем инцидент, чем быстрее мы реагируем на него, тем меньше ущерб. Это очевидный факт, который лежит в основе измерения эффективности многих центров мониторинга безопасности. Именно поэтому число инцидентов, а также временные параметры, связанные с ними, являются наиболее часто используемыми метриками при оценке эффективности современного SOC.
Если мы посмотрим на временную шкалу любого инцидента, то увидим, что ее можно разбить на несколько ключевых так называемых реперных точек, характеризующих инцидент. Начинаем мы с момента реализации угрозы, затем переходим к факту обнаружения инцидента или угрозы с помощью используемых нами решений или за счет обращения пользователя и отправки в SOC соответствующего сигнала тревоги. Продолжая, мы переходим к моменту начала приоритизации инцидента, позволяющего нам приоритизировать и усилия по реагированию, не размениваясь по мелочам и не тратя время и иные ресурсы на борьбу с ветряными мельницами в ущерб более серьезным для бизнеса инцидентам. Завершается временная шкала фактом закрытия инцидента и устранением причин, повлекших за собой появление инцидента, попавшего в центр мониторинга.
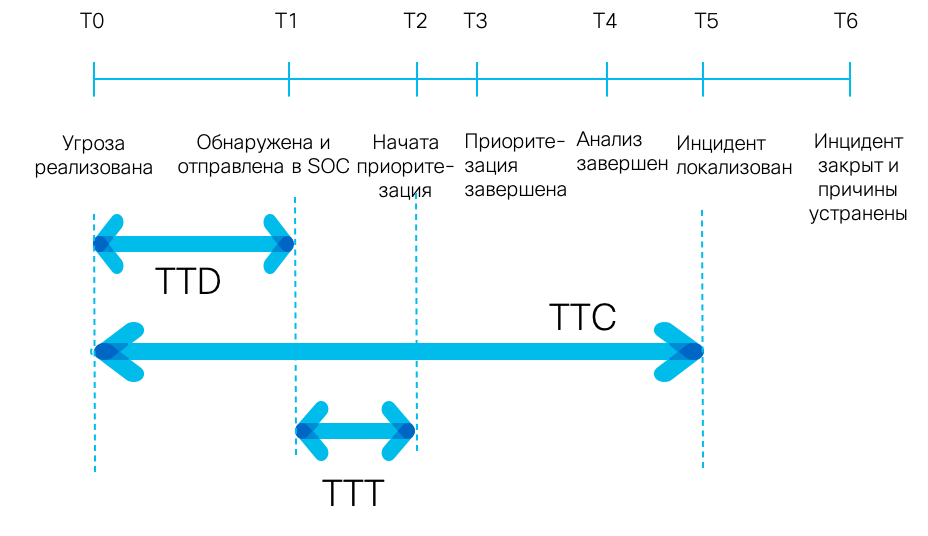 Большинство SOC, к сожалению, очень хорошо умеет вычислять число инцидентов событий с течением времени, но очень плохо занимается измерением непосредственно временных метрик, а точнее конкретных показателей на показанной временной шкале. Указанные три основные временные метрики (Time-to-Detect, Time-to-Triage, Time-to-Contain) на самом деле представляют только верхушку айсберга. Число временных метрик, в зависимости от этапа проведения анализа и расследования инцидента, может быть разным. Например, если свести все этапы работы с инцидентом в таблицу и визуализировать их, то мы поймем, что измерять мы можем любые временные интервалы между всеми указанными этапами, выявляя слабые места в наших процессах реагирования на инциденты.
Большинство SOC, к сожалению, очень хорошо умеет вычислять число инцидентов событий с течением времени, но очень плохо занимается измерением непосредственно временных метрик, а точнее конкретных показателей на показанной временной шкале. Указанные три основные временные метрики (Time-to-Detect, Time-to-Triage, Time-to-Contain) на самом деле представляют только верхушку айсберга. Число временных метрик, в зависимости от этапа проведения анализа и расследования инцидента, может быть разным. Например, если свести все этапы работы с инцидентом в таблицу и визуализировать их, то мы поймем, что измерять мы можем любые временные интервалы между всеми указанными этапами, выявляя слабые места в наших процессах реагирования на инциденты.

Такая декомпозиция временных параметров будет полезна и на нижележащих уровнях, например при оценке эффективности работы по конкретному Рlaybook (руководству по конкретному типу инцидента). Допустим, у вас есть Рlaybook для анализа подозрительной активности пользователя и среднее время реагирования на нее (от момента получения сигнала в SIEM и до замораживания учетной записи в AD, помещения узла в карантинный VLAN и поиска других узлов и пользователей, которые могли быть связаны с пострадавшим) у вас занимает около 28 мин. Вы смотрите статистику по отработанным инцидентам и видите, что этот показатель немного скачет в диапазоне от 19 до 37 мин., но в среднем составляет те же 28 мин. Вроде все в порядке. Но если бы у вас была возможность мониторить все отдельные шаги/задачи Рlaybook, то вы бы увидели, что вместо традиционных 1--3 мин. на выявление индикаторов, 1--3 мин. их проверки в TI-платформе, 1--2 мин. на принятие решения, 3 мин. на замораживание учетной записи в AD и т.п. ваш аналитик сразу после получения сигнала тревоги помещает пользователя и его узел в карантин, а то и вовсе без проверки передает инцидент на следующий уровень, аналитикам второй линии (L2). И вообще непонятно что аналитик делал оставшиеся 9--10 мин. То ли он пошел на кухню налить себе кофе, то ли он решил посмотреть новости на смартфоне, а может он просто отправился проветриться или посмотреть на солнце после нескольких часов "самоизоляции" в душном помещении. Но имеющаяся у вас метрика по конкретному инциденту соблюдена. Поэтому так важно оценивать не процесс целиком, а его отдельные этапы, проводя декомпозицию.
Средние значения
Кстати, вы заметили, что аббревиатуры, описывающие метрики, начинаются с буквы M? Это сокращение от Median, то есть не среднее арифметическое, а медиана, которая гораздо лучше покажет, насколько часто параметры выходят за средний показатель.
Почему мы говорим о медианных значениях, а не о среднем арифметическом? Этот показатель лучше отражает временные показатели в больших выборках с широким разбросом значений. Именно он, а не среднее арифметическое, которым так часто манипулируют. Например, вы встречаете в каком-нибудь отчете тезис, что средняя сумма инцидента ИБ составляет 11 млн руб. (цифра взята с потолка). Авторы отчета умалчивают, что они имели в виду под средним, но чаще всего они, недолго думая, просто делят сумму по всем инцидентам на число инцидентов. Является ли это действительно средним? Увы. В данной ситуации средним должна быть медиана -- именно она наиболее точно показывает среднестатистическую компанию. Давайте проиллюстрирую.
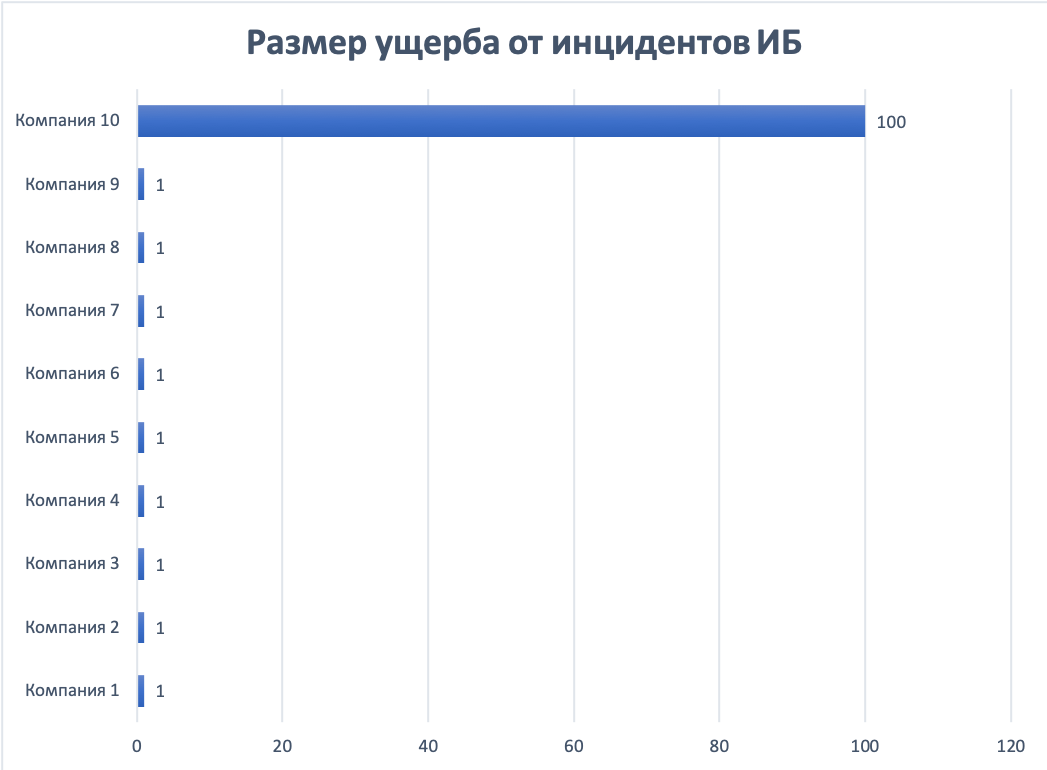
Представим, что у нас 10 компаний сообщили об инцидентах ИБ. У девяти компаний размер ущерба составил 1 млн руб., а у десятой -- 100 млн руб. Среднее арифметическое будет равно 10,9 млн, а вот медиана -- одному миллиону. И именно медиана отражает реальную картину размера ущерба (медиана может совпадать со средним арифметическим при симметричном распределении сумм ущерба у компаний).
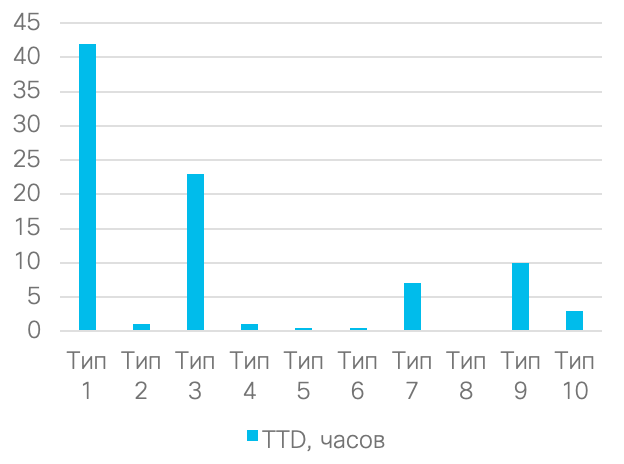
Другой пример. Мы измеряем среднее время обнаружения инцидента, то есть метрику Time-To-Detect (TTD). Среднее арифметическое для данного графика будет 8,81 часа. Но значит ли это, что оно действительно среднее? Нет. Медиана, то есть типичное значение TTD, будет в данном примере равно двум часам. При этом худший показатель TTD будет равен 42, а лучший -- 0,1 часа на обнаружение.
Но стоит помнить, что для разных угроз/инцидентов эти значения будут разные (хотя их и можно свести к некому единому показателю). Это по требованиям ФСБ в ГосСОПКУ данные передаются в течение 24 часов с момента обнаружения (хотя правильнее говорить регистрации) инцидента независимо от его природы. Но мы с вами прекрасно понимаем, что время обнаружения спама, время обнаружения группировки Cobalt и время обнаружения соединения с командными серверами ботнетов могут сильно различаться. Поэтому временные метрики обычно имеет смысл еще разделять по дополнительным атрибутам, о чем мы поговорим дальше.
Примеры временных метрик
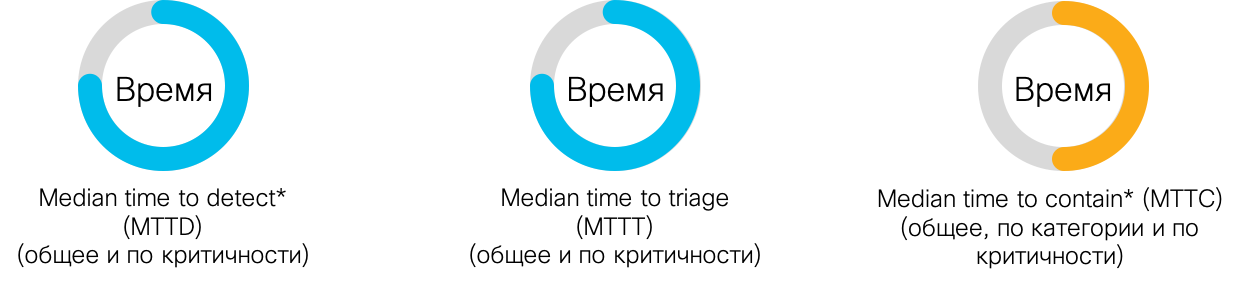
Давайте посмотрим на примеры временных метрик. Первая и самая очевидная метрика -- это медианное время для обнаружения инцидента, которое я уже упоминал выше. Это наиболее типичный временной интервал, в течение которого SOC начинает реагировать на инцидент. Более длительное значение этой метрики указывает на более высокие уровни ущерба (дольше не видим -- больше теряем). Отслеживание этого показателя поможет нам настроить ИБ-инструментарий, улучшить возможности обнаружения инцидентов или увеличить охват сбора данных. Целью измерения данной метрики у нас является минимизация времени на обнаружение. Иными словами, чем быстрее мы обнаруживаем инцидент, тем быстрее, как минимум в теории, мы на него начинаем реагировать и тем быстрее его закрываем и, соответственно, тем меньше ущерб, наносимый компании.
Время приоритизации
Следующая интересная метрика, которая может быть использована в SOC, -- это медианное время на приоритизацию инцидента. Это среднее время, необходимое центру мониторинга для начала реагирования на инциденты с момента получения сигнала тревоги. Более длинный показатель указывает на более высокие уровни ущерба и неспособность аналитиков своевременно включаться в работу. Иными словами, я получаю сигнал тревоги, но проходит слишком много времени, прежде чем я пойму, что означает для моей компании этот сигнал тревоги. Причиной может служить отсутствие у меня соответствующих Рlaybook, и мне их надо будет разработать. Возможно, у меня отсутствуют соответствующие правила приоритизации и классификации тех или иных инцидентов по важности, срочности, серьезности или по каким-то иным параметрам. В любом случае это очень важный параметр для измерения эффективности SOC.
Время локализации
Наконец, еще одна важная временная метрика, связанная с SOC, -- это среднее время, в течение которого SOC локализует инцидент. Разумеется, он отсчитывается с момента своего начала. Более длинные значения метрики указывают на более высокие уровни ущерба, которые несет наша компания.
В идеале нам надо смотреть еще глубже и оценивать не просто время реагирования, время приоритизации, время локализации и т.п., а делать это применительно к разным типам инцидентов, да еще и для разных аналитиков (новичок и бывалый должны иметь разные временные показатели -- второй должен работать быстрее).
Число инцидентов
Идем дальше. Следующей интересной метрикой является число инцидентов, обнаруженных с помощью Threat Intelligence. Отслеживание этого показателя показывает ценность применяемых нами фидов, а также провайдеров Threat Intelligence, которыми мы пользуемся и за работу которых мы платим деньги. Эта метрика также может показать, насколько интегрированы подразделения TI и мониторинга в SOC. Может оказаться так, что и фиды у нас качественные, и провайдеры не зря получают от нас деньги, но полученная от них информация не используется при обогащении инцидентов в SIEM, не используется в рамках Threat Hunting, не применяется при расследовании.
Выигрыш от автоматизации
Еще одна интересная метрика -- это число часов, сохраненных инструментами автоматизации. Она показывает ценность автоматизации, а также дает представление о том, какие инструменты автоматизации дают эффект, а какие не дают. Ну и конечно, она показывает, насколько данные инструменты эффективно используются разными аналитиками SOC, что позволяет выстроить для них личные планы обучения и повышения квалификации.

Читайте продолжение в журнале "Информационная безопасность" №3, 2020.










