






Дмитрий Евдокимов, 01/08/25
Давайте без иллюзий: образы контейнеров без проблем и уязвимостей – миф. Даже если такой момент и наступает, это либо исключение, либо временное затишье. Но это точно не повод игнорировать безопасность. Напротив, к ней нужно подходить с умом, иначе ресурсов на реальное улучшение просто не хватит.
Автор: Дмитрий Евдокимов, основатель и технический директор Luntry
База: Образы контейнеров
Чтобы не быть голословными, давайте сначала разберемся, что такое образы контейнеров, из чего они состоят и как мы получаем ситуацию, описанную выше.
По сути, образ контейнера – это архив в котором содержится приложение и все необходимые для его работы объекты: сторонние библиотеки, библиотеки для библиотек (и далее вглубь), файлы, директории, сторонние программы.
С учетом того, что современные микросервисы на 60%–90% состоят из стороннего кода – в образах содержится очень много того, что писали и создавали не вы, а кто-то другой. Но! Все это теперь находится внутри вашего образа и влияет на общую безопасность микросервиса, то есть входит в вашу зону ответственности. Стоит добавить, что содержимое добавляется в образ не одним скопом, а по слоям. Из этих слоев обычно строится несложная иерархия. Сначала идет базовый слой – обычно это слой ОС (например, Ubuntu, Debian, Astra Linux, ОС "Альт") со всеми ее компонентами. Дальше идет слой с рантаймом языка программирования и его зависимостями (например, Java, Python, Ruby). Далее идет слой (или слои) со сторонними библиотеками, которые являются зависимостями для вашего приложения (например, React, Spring, OpenSSL). И в заключении – ваше приложение, которое функционирует на базе всего, что находится в нижележащих слоях.
Поскольку идеальных приложений не существует, каждое из них содержит уязвимости, которые регулярно выявляются. Среди них встречаются как критически важные и действительно опасные, так и те, что никак не применимы к вашему конкретному случаю. Кроме того, на управление уязвимостями влияет множество дополнительных факторов, усложняющих этот процесс. О них мы тоже поговорим.
База: Жизненный цикл уязвимости
Теперь давайте разберемся с классическим жизненным циклом любой уязвимости с того момента, когда она выявляется, до того момента, как с помощью сканера мы находим ее в своей кодовой базе и выпускаем исправление.
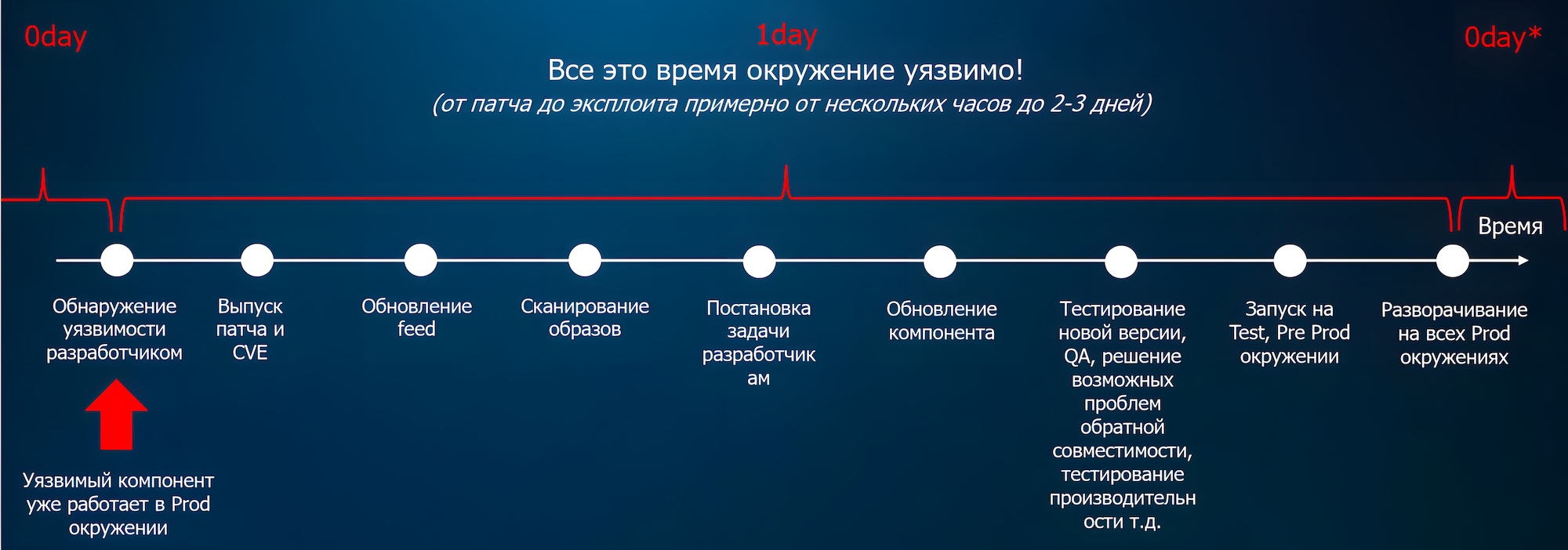
Рис. 1. Жизненный цикл уязвимости
Фаза 1: Обнаружение уязвимости разработчиком. Это может случиться при внутреннем или при внешнем тестировании, из программы баг-баунти, из инцидента безопасности у кого-то из ваших заказчиков. Важно понимать, что на текущий момент: 1) это уязвимость 0-day и для нее еще нет исправления, и 2) эта уязвимость есть у всех пользователей данного компонента.
Фаза 2: Выпуск патча и идентификатора CVE. Разработчик начинает работу над проблемой: анализирует уязвимость, готовит исправление, проводит тестирование, выпускает патч. Параллельно может происходить регистрация CVE – хотя это не гарантировано. Многое зависит от качества описания и желания разработчика признавать критичность: по понятным причинам ее нередко стремятся занизить. На этом этапе уязвимость переходит из статуса 0-day в статус 1-day.
Фаза 3: Обновление feed-уязвимостей. Разработчики Security-решений обновляют свои базы знаний (feed) с актуальной информацией об уязвимостях. Например, в Luntry [1] это происходит ежедневно. На стороне заказчика такие обновления тоже должны применяться: где-то это происходит автоматически, где-то – требует дополнительной автоматизации, особенно в закрытых контурах. Чем чаще происходит обновление, тем более свежими и релевантными данными вы располагаете.
Фаза 4: Сканирование образов. Лишь теперь можно приступать к сканированию образов, чтобы выявить уже известную уязвимость. Здесь важно, насколько полно ваше окружение охвачено сканерами, с какой периодичностью запускается сканирование, сколько у вас образов и каковы их размеры – все это влияет на длительность анализа. Добавим к этому и привычные уловки разработчиков, стремящихся пройти Quality Gate с первого раза, в том числе за счет обхода сканеров. Всё перечисленное напрямую влияет на скорость и точность выявления уязвимостей. А при этом в продакшене всё еще остается микросервис с уязвимостью, и атакующий уже в состоянии ее эксплуатировать!
Фаза 5: Постановка задачи разработчикам. Обнаружение уязвимости – это лишь 10%–15% всей работы. Основная сложность начинается позже: с постановки задачи на исправление. Этот процесс может быть как ручным, так и автоматизированным, однако в некоторых окружениях мы наблюдаем сотни тысяч уязвимостей. Возникает необходимость приоритизировать: какие проблемы критичны и требуют немедленного реагирования, а какие могут подождать. Без этого хаос быстро парализует весь процесс.
Фаза 6: Обновление компонента. Спустя какое-то время разработчик добирается до задачи, связанной с устранением уязвимости. В зависимости от внутренних процессов компании это может занять от пары дней до нескольких месяцев – зависит от ритма спринтов, заморозок, внутренних регламентов. И если кажется, что все сводится к обновлению версии компонента с младшей на старшую, то вы сильно ошибаетесь. На деле возникает масса сложностей: обратная несовместимость, каскадные зависимости, конфликты с другими компонентами и микросервисами. В результате даже первая версия с исправлением может потребовать немалого времени на подготовку. А тем временем уязвимый сервис по-прежнему работает в продакшене.
Фаза 7: Тестирование новой версии. Разумеется, никто (по крайней мере, хочется в это верить) не выкатывает новую версию сразу в продакшен. Сначала ее проверяют тестировщики: прогоняют через регрессионные и нагрузочные тесты, оценивают стабильность, производительность, совместимость. Если возникают проблемы, компонент уходит на доработку. А время по-прежнему работает против нас.
Фаза 8. Выкатка на Test- и PreProd-окружения. Если тестирование прошло успешно, начинается поэтапный выпуск новой версии: сначала в Test-, затем в Pre-Prod-окружения. Этот процесс тоже занимает время, и, как и раньше, оно жестко играет против нас.
Фаза 9. Разворачивание на Prod-окружениях. И только теперь, спустя N дней или даже месяцев, начинается выкатка обновления в продакшен. Этот этап тоже не так прост, как может показаться. Его сдерживают регламентные окна, циклы обновлений, необходимость поэтапного развертывания, особенности сегментации и доступности разных кластеров. В крупных распределенных инфраструктурах обновление не происходит по щелчку пальцев – это сложный и чувствительный процесс.
Фаза 10. Все сначала. Мы описали лишь упрощенный пример – одну уязвимость в одном компоненте одного микросервиса. В реальности таких случаев на порядки больше. Этот процесс никогда не прекращается: с каждой новой версией компонентов появляются новые уязвимости. Работа по их выявлению и устранению непрерывна. Это по сути бесконечный цикл.
Решение 1: Приоритизация уязвимостей (реактивный подход)
Исправить абсолютно все уязвимости невозможно – да и не нужно. Значительная их часть никак не влияет на безопасность микросервисов: это могут быть неиспользуемые исполняемые файлы, библиотеки или пути в коде, которые не задействуются конечным приложением. Такие случаи – типичный False Positive. Мир уже отошел от парадигмы полной нетерпимости к уязвимостям (Zero Tolerance). В ее рамках вы бы не выпустили ни одного релиза и ни одного продукта.
В первую очередь необходимо закрывать те уязвимости, через которые злоумышленник с наибольшей вероятностью сможет нанести реальный ущерб. Для этого критично уметь приоритизировать результаты сканирования. В Luntry мы выделяем и предоставляем следующие критерии для такой приоритизации:
- CVSS (Common Vulnerability Scoring System) – классическая оценка уровня уязвимости, база.
- Severity – критичность уязвимости.
- Type (RCE/DoS) – тип уязвимости. В микросервисной среде нас интересуют в первую очередь сетевые векторы.
- Exploit – наличие в публичном доступе готового эксплойта. Это резко повышает риск: уязвимость становится легко воспроизводимой, провоцирует массовые атаки и серьезно увеличивает вероятность инцидента.
- KEV (Known Exploited Vulnerabilities) – наличие уязвимости в базе инцидентов, подтверждающих ее реальное использование в атаках. Это означает, что уязвимость уже эксплуатируется злоумышленниками "в поле", и риск ее эксплуатации в вашей инфраструктуре крайне высок.
- EPSS (Exploit Prediction Scoring System) – это система оценки вероятности эксплуатации уязвимости в будущем.
- Runtime – подтвержденное наличие уязвимости в компонентах, запущенных в продакшене. Такой подход позволяет сосредоточиться на реально работающих и потенциально уязвимых элементах, исключая из анализа неиспользуемый код.

Рис. 2. Фильтрация уязимостей в Luntry
Такая приоритизация позволяет сократить объем задач для разработчиков с десятков тысяч до считанных десятков. Это экономит время всех команд и значительно ускоряет повышение реального уровня безопасности, фокусируя усилия на том, что действительно важно.

Рис. 3. Результат фильтрации уязимостей в Luntry
Можно пойти дальше и подключить другие подсистемы Luntry – например, определить, находится ли уязвимый сервис на поверхности атаки или защищен компенсирующими мерами. Эти факторы дополнительно снижают вероятность успешной атаки и, соответственно, позволяют понизить приоритет на исправление.
Решение 2: Уменьшение поверхности атаки (проактивный подход)
В этом случае мы делаем так, чтобы при наличии известных или даже неизвестных уязвимостей через них было бы невозможно или чрезвычайно сложно нанести ущерб. В этой парадигме Luntry позволяет:
- С помощью контролей микросервисов запускать только доверенные микросервисы, соответствующего уровня безопасности, что не позволит внутреннему нарушителю выкатить приложение не соответствующего уровня безопасности.
- С помощью политик предотвращения создать список только доверенных процессов, что приводит к тому, что атакующий не способен запустить свой вредоносный код.
- С помощью автоматической генерации и применения Network Policy, реализовать микросегментацию для создания Zero Trust-модели между микросервисами. Таким образом, атакующий не сможет что-то загрузить или выкачать из вашей сети.
В результате это дает дополнительное время на устранение уязвимости – без риска быть скомпрометированным в процессе. Команды могут работать спокойнее и системнее, не жертвуя безопасностью ради срочности.
А вывод?
Вывод такой: в современных реалиях необходимо грамотно сочетать проактивный и реактивный подход с приоритизацией. Только такой комплекс мер позволит дать реальный прирост уровня безопасности на деле, а не на бумаге.
Реклама: АО «КлаудРан». ИНН 7804715379. Erid: 2SDnjdZZwz6








