






Валентина Пугачева, 07/07/22
Мы в отделе разработок алгоритмов машинного обучения Security Vision поставили перед собой задачу: научиться детектировать нетипичные события в сетевом трафике для выявления новых типов атак, не замечаемых другими системами защиты. Искать нетипичные события можно классическими детерминированными методами – моделями на основе знаний об известных атаках, о типичном и атипичном поведении, с использованием белых и черных списков. Такие модели вполне эффективны, но они не позволяют находить новые виды нетипичных событий, а также требуют частого адаптирования как под меняющуюся инфраструктуру, так и под непостоянный характер трафика. Поэтому в качестве основного математического аппарата мы выбрали модели на основе машинного обучения, которые очень хорошо подходят для такой постановки задачи благодаря своей обобщающей способности и механизмам адаптации к изменениям.
Автор: Валентина Пугачева, ведущий разработчик алгоритмов машинного обучения компании Security Vision
Поскольку нам требовался взгляд за пределы типовых атак, то мы сразу отказались от использования размеченных обучающих выборок с известными атаками – это не дало бы требуемого эффекта. Для детектирования аномалий в сетевом трафике мы выбрали метод тренировки модели без учителя. Таким образом, исходные данные для модели не были размечены, то есть для каждого события априори не было известно, является ли оно аномальным или нет.
В ходе исследования для решения задачи нами были опробованы наиболее популярные методы машинного обучения, включая кластеризацию, Local Outlier Factor, Isolation Forest, One Class SVM. Причем вполне допускалось, что в итоге мог остаться не только один алгоритм: использование нескольких методов, которые бы работали независимо друг от друга, дало бы более широкую картину и позволило бы задействовать достоинства каждой модели. Например, метод One Class SVM хорошо находит новые события, но уязвим к отравлению обучающей выборки. С другой стороны, Isolation Forest лишен такого недостатка, но не так эффективно работает со входными данными.
Одна часть алгоритмов в результате исследований оказалась в финальном решении, другая часть была отбракована или отложена в бэклог либо из-за особенностей реализации на практике, либо из-за избыточных требований к вычислительным ресурсам.
У нас также отсутствовала экспертная оценка ожидаемого количества аномалий, что повлияло на особенности применения алгоритмов и создавало дополнительную сложность в проверке качества получаемой модели.
Кроме того, нам важно было детектировать аномалии не постфактум, а в реальном времени, да еще и в большом потоке событий, порядка 105 событий в секунду.
В результате была создана система, объединяющая несколько моделей на основе машинного обучения и решающая поставленную задачу в условиях описанных ограничений. Пришла пора проверить систему на практике.
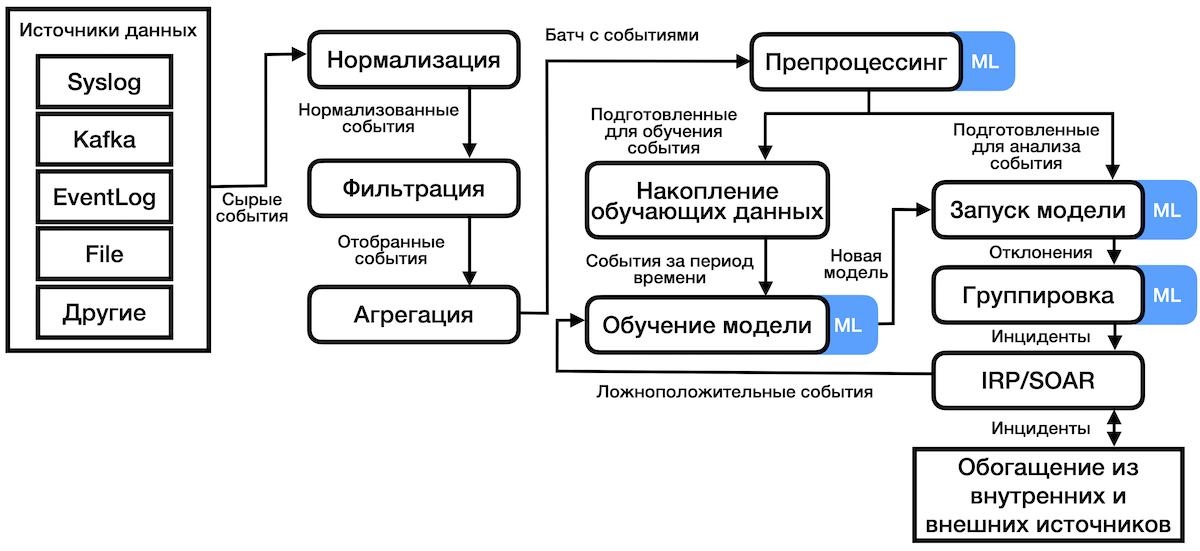 Рис. Получение и обработка данных
Рис. Получение и обработка данных
Проверка практикой
Сырые ненормированные данные поступали на вход моделей из различных ИБ-систем, аккумулирующих сетевые события, таких как межсетевые экраны и SIEM. Каждая система выдавала события с изначально разными признаками, поэтому в итоге мы остановились на самом базовом наборе: ip-адресa, порты, протокол, количество переданных байтов – именно на основе этих данных и строились модели. Для объединения определенных моделью как отклонения событий в инциденты мы использовали кластеризацию.
Важный практический вопрос: сколько времени должно пройти, прежде чем система начнет выдавать первые результаты?
В нашем случае алгоритмы начинают выдавать результаты практически сразу, как только система начинает работу. Первый пакет накапливается за одну минуту, он отправляется в модуль предсказания, который выдает результат. Может потребоваться первичная настройка параметров модели, но такие ситуации редки.
Конечно же, чем чище система от вредоносной активности в период обучения, тем точнее проходит обучение наша модель.
Метод One Pass SVM и статистическая модель, работающие в системе, накапливают достаточную обучающую выборку от несколько часов до семи дней. Такой период обучения позволяет также учесть недельную цикличность работы сети, ведь трафик в выходные дни заметно отличается от рабочего.
При этом модель принудительно переобучается каждые сутки на ретроспективных данных за прошедшую неделю, адаптируясь к меняющемуся трафику. Переобучение каждой модели происходит независимо от работающей копии, так что новая модель заменяет текущую после обучения, что позволяет системе продолжать непрерывно работать в реальном времени.
В результате такого режима обучения система выделяет в реальном трафике широкий спектр аномальных событий, из которых формируются инциденты, прошедшие незамеченными для штатных СЗИ: сканирования, атаки, инфраструктурные проблемы, обращения к торрентам, элементы DDoS-атак и даже майнинг криптовалюты.
При этом со стороны заказчика не требуются дополнительные человеческие ресурсы для того, чтобы использовать систему с машинным обучением. Мы изначально закладывали высокий уровень автоматизации: система сама подключается к источникам данных и продолжает работать в автономном режиме. Результаты передаются в SIEM или IRP/SOAR заказчика.
False Positive и False Negative
Использованные нами методы машинного обучения достаточно прозрачны, и получаемым результатам вполне можно доверять. При этом система не становится заложником качества учителя или обучающей выборки, как в случае использования нейросетей – они могут быть отравлены некорректным обучением или оказаться неустойчивыми в случае сильного отклонения трафика от обучающего.
В качестве проверки на этапе экспериментов мы добавляли во входные данные априорные аномалии и добивались, чтобы такие вручную добавленные события выявлялись системой в полном объеме.
При этом уровень False Positive принципиально оценить довольно сложно, ведь классические метрики для нашего случая не подходят из-за отсутствия разметки входных данных. Поэтому мы перешли на оценку False Positive по обратной связи от заказчиков. Например, после работы модели в течение нескольких недель обнаруживались 10–20 инцидентов в неделю. Все они автоматически отправлялись в SIEM заказчика и анализировались специалистами. Часть инцидентов были отнесены к False Positive, часть – к инфраструктурным инцидентам, часть – к вредоносной активности. Информация о такой квалификации инцидентов снова поступает на вход модели, и эта обратная связь позволяет ей дообучаться под конкретные инфраструктурные условия и за счет этого повышать качество своей работы.
Впрочем, из общения с заказчиками мы знаем, что некоторое количество ложноположительных инцидентов даже полезно, поскольку это придает уверенность в том, что опасные аномалии точно были обнаружены.
Отмечу, что даже те события, которые были отнесены заказчиком к False Positive, – это не случайные ошибки, а также нетипичные события, хотя и оказавшиеся легитимными в конкретных условиях. Поскольку инфраструктура заказчика живет и функционирует, у нее есть типовое поведение, но также присутствуют и редкие процессы, которые мы как раз и выделяем в аномалии.
Перед тем как основе данных о найденных отклонения создавать новые инциденты в SIEM или SOAR, система учитывает уже существующие инциденты. Это делается, во-первых, чтобы не дублировать аналитические данные, а во-вторых, при возможности обогатить существующий инцидент полученной информацией.
Планы развития
Разработка модели стала для компании Security Vision первым опытом анализа сетевого трафика. Пока мы видим эту функциональность как дополнительный слой, который хотя и не заменит существующие системы защиты, но позволит увидеть совершенно атипичные события, пропущенные другими системами.
При этом наша разработка оформлена в готовый коробочный продукт, который незамедлительно может приступить к работе в реальной инфраструктуре заказчиков.
Но работа по развитию системы продолжается. Мы добавляем в модель процессинг новых типов более высокоуровневых событий, повышаем степень автоматизации и автономности, включаем новые модели. Возможно, мы также попробуем использовать нейронные сети в качестве одного из модулей.
Важно понимать, что, когда мы используем знание только об известных атаках, обучаясь на ретроспективно размеченных данных, мы оказываемся на шаг позади атакующих. Но если заглянуть вперед, скажем на три года, то можно увидеть, как методы машинного обучения без учителя полноценно дополняют другие СЗИ, выявляя новые, не известные ранее типы атак. Системы, основанные на элементах искусственного интеллекта, конечно, вряд ли в обозримом будущем полноценно заменят даже первую линию SOC, но уже сейчас они могут стать полезным и даже обязательным инструментом для специалистов по информационной безопасности.








