






Андрей Пинчук, 28/12/20
Интернет и онлайн-услуги проникли во все отрасли нашей жизни. Банковская сфера – не исключение. Через удаленные каналы можно оплатить покупку или открыть вклад, получить кредит без визита в офис банка или совершить перевод через чат-бота в мессенджере. Однако вместе с распространением новых платежных инструментов растет и интерес мошенников к этим сервисам.
Автор: Андрей Пинчук, исполнительный директор, начальник Отдела аналитической экспертизы Сбербанка
В Сбербанке реализована эшелонированная защита всех онлайн-услуг, которая включает в себя ряд защитных механизмов: подтверждение критичных операций одноразовыми паролями, шифрование трафика и др. Одним из ключевых элементов этой защиты является система фрод-мониторинга для выявления и предотвращения мошенничества.
В системе фрод-мониторинга Сбербанка используется целый ряд моделей на основе машинного обучения (ML-моделей), направленных на противодействие различным аспектам кибермошенничества – выявление мошеннических транзакций и групп, а также совокупности этих моделей, что позволяет удерживать уровень мошеннических операций на минимальных показателях при постоянном росте транзакционной активности и появлении новых продуктов и услуг.
Вместе с тем мы в Сбербанке постоянно ищем пути повышения эффективности фрод-мониторинга, анализируем достижения в различных областях Data Science на предмет их применимости.
Почему графы?
Для банка в целом и для задачи противодействия мошенничеству в частности важно хорошо знать своих клиентов. Наряду с социально-демографическими признаками, оборотами и покупками клиентов не менее важную роль играют финансовые взаимодействия людей. Последнее – не что иное, как граф, где вершинами выступают клиенты (или внешние по отношению к банку реквизиты), а ребра между вершинами – это финансовые транзакции. Используя такой граф, можно получить много важной дополнительной информации для системы фрод-мониторинга.
В моделях фрод-мониторинга Сбербанка мы уже давно используем графовые данные, например графовые характеристики вершин и ребер (степени, общее число соседей между вершинами), пути между вершинами и т.д. Однако создание эвристик на графах требует привлечения фрод-аналитиков, что является очень затратным по времени. Обычно эвристики носят локальный характер – затрагивают вершину и ближайшее ее окружение (см. рис. 1). Также расчет эвристик более высоких порядков и длин путей в моделях real-time на объемах банка невозможен (~12 000 транзакций в секунду со временем SLA <100 мс). Поэтому необходим механизм, который позволял бы извлекать информацию из структуры графа автоматически и использовать ее для моделей фрод-мониторинга.
 Рис. 1. Популярные эвристики для предсказания возникновения связи в графе (Г(x) – вершины - соседи)1
Рис. 1. Популярные эвристики для предсказания возникновения связи в графе (Г(x) – вершины - соседи)1
Машинное обучение на графах
Зачастую для извлечения структурной информации из графов и передачи в традиционные ML-модели (регрессии, деревья решений и пр.) используется набор статистических данных, описывающих граф, kernel-функции для графов или разработанные аналитиками признаки. Ограничения такого подхода заключаются в том, что разработанные признаки не адаптируются под имеющиеся данные во время обучения, а создание новых признаков требует много времени.
В настоящее время разработано множество алгоритмов, направленных на обучение представлений (Representation Learning) графов. Суть Representation Learning – закодировать структурную информацию о графе в пространство меньшей размерности (так называемый embedding), например представить вершины графа или целиком граф (подграфы) как точки в новом графе. При этом цель алгоритма/модели – чтобы в получившемся пространстве геометрические соотношения отражали структуру исходного графа, например близкие вершины в пространстве были также близки (связаны ребром, имели небольшой кратчайший путь) в графе.
Ключевое отличие подходов Representation Learning от традиционных состоит в том, что последние самостоятельно на основании данных о графе ищут оптимальное представление в пространстве меньшей размерности (embedding), а не полагаются на заранее заданные эвристики.
Graph Representation Learning можно разделить на два класса – unsupervised и supervised (semi-supervised). Цель первых методов – выучить представление low-dimensional с сохранением структуры начального графа, вторых – получить представление low-dimensional, но только для определенной последующей задачи классификации, например классификации вершин графов или самих графов. В supervised-методах помимо самого графа передается дополнительная информация, описывающая вершины (так называемая Node Features).
Формулировка задачи и особенности графа Сбербанка
Для оценки эффекта от использования GRL-методов было принято решение взять несколько real-time-моделей, осуществляющих проверки переводов между клиентами банка или на сторонние реквизиты, дополнить их признаками по результатам работы GRL-моделей и оценить прирост эффективности. При этом использовались текущие промышленные модели, в которых приводились некоторые графовые метрики (наличие прямых связей, общие соседи). Это было сделано для того, чтобы оценить добавочный эффект, который могут дать GRL-методы в дополнение к базовым графовым эвристикам.
Тут важно отметить, что далеко не все GRL-методы хорошо масштабируются на большие графы (свыше нескольких сотен тысяч вершин). В экспериментах мы использовали граф из 250 млн вершин и 2,2 млрд ребер. Большинство разработанных GRL-методов не в состоянии обработать такой граф. Для решения задачи нами был проанализирован и отобран ряд решений, которые по своей временной сложности и архитектуре разрабатывались именно для задачи работы на гигантских графах.
По результатам анализа мы выбирали из решений Open Source GraphSAGE, SEAL, Pytorch BigGraph и решили остановиться на последнем решении, о причинах – ниже.
Pytorch BigGraph (PBG)
Pytorch BigGraph – решение Open Source от компании Facebook. PBG – это распределенная система для получения embedding для очень больших графов (по информации от разработчиков, до миллиардов вершин и триллионов ребер), что достигается за счет некоторых функций, а именно:
- партиционирования графа (позволяет обучать модели без необходимости загрузки всего графа в оперативную память);
- многопоточных вычислений;
- поддержки распределенного параллельного обучения на множестве машин на разных частях партиционированного графа;
- реализации пакетной обработки для операции негативного сэмплирования ребер (существенно ускоряет процесс обучения).
При этом все вычисления работают с использованием ресурсов исключительно CPU и не требуют специализированных GPU-серверов (для GraphSAGE и SEAL требуются GPU, поскольку в их основе лежат графовые сверточные сети), хотя возможность использовать GPU для обучения в последнем релизе также появилась.
Решение относится к unsupervised классу GRL (тогда как SEAL и GraphSAGE относятся к supervised). Соответственно, для получения embedding представления графа не требуется никаких дополнительных данных, описывающих вершины, что позволяет быстрее провести эксперименты и оценить результаты.
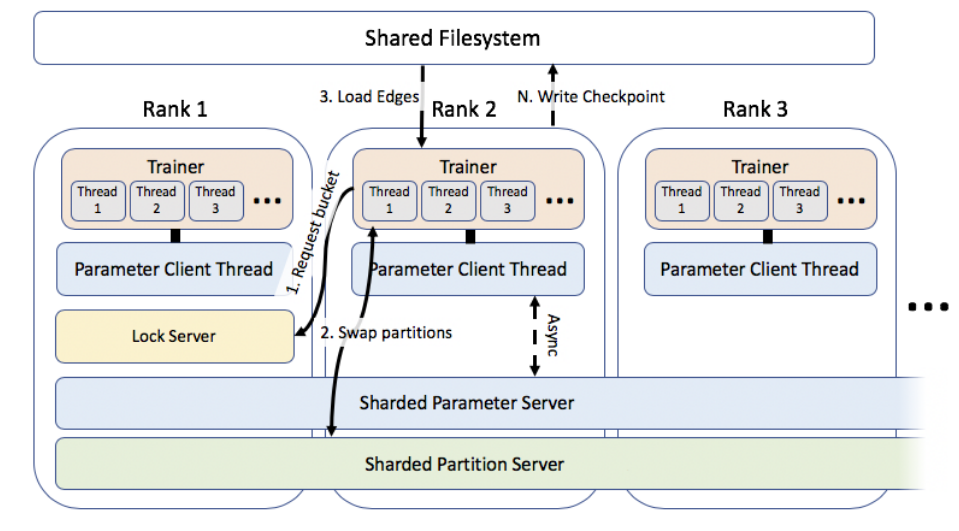
Рис. 2. Основные компоненты решения PyTorch BigGraph, использующиеся для распределенного обучения2
PBG поддерживает работу с мультисущностными и мультиреляционными графами, то есть позволяет обрабатывать графы, в которых представлены вершины разных типов и разные типы связей, например граф связей физических и юридических лиц (разные типы сущностей), а связи – финансовые транзакции и факт владения юридическим лицом. Решение является законченным, стабильным, и оно было неоднократно опробовано на больших графах в сотни миллионов вершин как разработчиками, так и сообществом. Оно показало хорошие результаты по скорости работы и качеству результата. Имплементации GraphSAGE и SEAL присутствуют в виде библиотек или как часть более общих фреймворков для работы с графами (например, Pytorch Geometric), но всетаки это незаконченные продукты, и для их использования придется дополнительно реализовать часть функционала по обработке графа. В результате мы решили для первых экспериментов с GRL остановиться на решении Pytorch BigGraph.
Данные для эксперимента и подход к оценке эффекта от GRL В Сбербанке уже давно реализован и активно используется для противодействия мошенничеству граф связей, содержащий более 800 млн вершин и более 3 млрд ребер, а также свыше 30 различных типов связей. При этом граф обновляется на ежедневной основе, а исторические слепки графов с заданным шагом хранятся в Hadoop-кластере, что очень важно для разработки моделей и получения корректных оценок эффективности.
Для нашей задачи на первом этапе мы отобрали в графе только тип связи "переводы" и вершины, соответствующие клиентам банка и сторонним реквизитам (карты, счета в других банках). Глубину транзакций ограничили одним годом. Таким образом мы получили граф G (V, E), где V – это множество вершин, а E – множество ребер. Ребро между вершиной i и j существует, если в отобранном временном промежутке проводилась хотя бы одна подходящая транзакция. На этом этапе мы не стали фильтровать ребра ни по суммам, ни по количеству переводов, хотя такая возможность присутствует. Общее число вершин в получившемся графе – свыше 250 млн, а ребер – свыше 2,2 млрд.
Оценку эффекта решено было провести на основных real-time-моделях оценки риска переводов в ДБО, которые находятся в промышленной эксплуатации. Были выбраны именно модели переводов, потому что в них присутствуют отправитель и получатель, которые как раз являются вершинами в нашем графе. Для обучения этих моделей использовались их же конвейеры (Pipelines) формирования обучающей выборки, подготовки и отбора признаков (включая графовые эвристики), подбор гиперпараметров. Глубина обучающей выборки – четыре месяца (с мая по август 2020 г.), в нее включены все мошеннические переводы клиентов в каналах ДБО (выявленные и пропущенные текущим финансовым мониторингом) и случайная выборка переводов в соотношении 50:1.
Для оценки прироста эффективности был выработан следующий поэтапный подход:
- Производится обучение модели через существующие конвейеры, затем на отложенной по времени части выборки оценивается эффективность моделей (точность при заданном уровне полноты выявления мошенничества, ROC AUC).
- В существующий конвейер обучения в качестве дополнительных признаков добавляется эмбеддинг вершин, полученных с помощью применения Pytorch BigGraph к графу.
- Происходят сравнения близости (косинусная близость, скалярное произведение) эмбеддингов отправителя и получателя в переводе. При этом все эмбеддинги должны быть получены на графах до момента проведения транзакций.
- Производится обучение тех же моделей, но уже на расширенном наборе признаков. Оцениваются значимость добавленных признаков для модели и ее эффективность.
- Производится сравнение эффективностей моделей без GRL-признаков и с ними.
Эксперименты по построению Graph Embedding
Для применения Pytorch BigGraph сначала необходимо сконвертировать граф в специальный формат, с которым работает решение. К сожалению, в самом решении реализован только базовый метод конвертации, работающий крайне медленно и в однопоточном режиме. Конвертации среза нашего графа этим методом, по оценкам, заняла бы семь дней. Авторы решения пишут, что реализация механизмов конвертации остается за пользователем решения (из-за большого числа разных систем хранения и форматов) и в документации подробно описан необходимый формат файлов. Поэтому мы сами реализовали метод, который конвертирует срезы нашего графа из Hadoop в требуемый формат. В результате конвертация среза графа выполняется всего за тридцать минут.
Для проведения экспериментов с Pytorch BigGraph использовался сервер следующей конфигурации: 7 CPU с 8 ядрами и 750 GB RAM. С учетом доступной оперативной памяти сервера и других запущенных на сервере процессов при конвертации слепков нашего графа в требуемый формат мы партиционировали его на 20 частей. При серверах с меньшей доступной памятью или большими по размеру графами можно увеличить данный параметр.
Pytorch BigGraph предоставляет большое число параметров для обучения модели представления графов (например, размерность эмбеддингов, функцию потерь, функции сравнения близости). Мы решили использовать предлагаемые разработчиками базовые параметры, а размерности эмбеддингов (размерность пространства в которых будут размещены вершины графа) установить равной 256. Это компромисс между скоростью обучения, итоговым размером эмбеддингов и возможностью закодировать максимум информации из нашего графа.
Подготовив первый срез графа, мы сначала посмотрели, какое время у нас займет одна эпоха обучения. С учетом описанной конфигурации сервера и параметров одна эпоха обучения заняла приблизительно 1,5 дня. Затем мы решили посмотреть, сколько эпох обучения потребуется, чтобы модель Pytorch BigGraph обучилась и с какого момента качество модели (ROC AUC в данном случае) перестанет расти. Для этого мы запустили обучение модели PBG на шести эпохах и получили следующие графики ROC AUC/loss-функции (одна эпоха – примерно 210 групп вершин) (см. рис. 3 и 4).
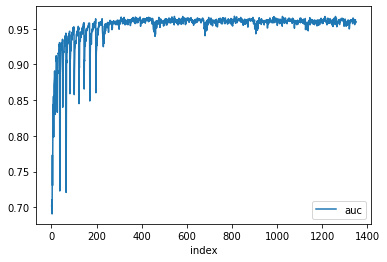
Рис. 3. Зависимость ROC AUC от числа групп вершин обучения модели
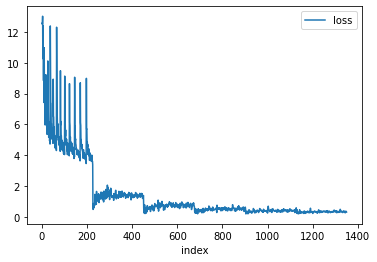
Рис. 4. Зависимость функции потерь модели (ranking loss по умолчанию) от числа групп вершин обучения модели
Из графиков видно, что в целом уже после трех эпох обучения (около 650 групп вершин) значения ROC AUC и loss-функции выходят на плато и практически не изменяются. Поэтому для построения embedding на срезах графа мы решили обучать модели в течение трех эпох, таким образом на построение embedding одного среза графа уходит примерно четыре-пять дней.
Сам embedding графа размерностью 256, то есть представление каждой вершины графа в виде вектора из 256 вещественных чисел, занял около 300 Гбайт на HDD. Для примера мы визуализировали 1 млн случайно выбранных вершин на плоскости с помощью алгоритма снижения размерности umap. В целом даже на 1 млн случайных вершин видны кластеры плотно взаимодействующих вершин (см. рис. 5).

Рис. 5. Отображение случайного 1 млн вершин на плоскость (с помощью алгоритма снижения размерности umap)
Построение embedding на срезах графа и применение в моделях скоринга переводов
С учетом времени, которое требуется для получения embedding среза графа (4-5 дней), мы решили поступить следующим образом: было выбрано четыре среза графа на конец каждого месяца (апрель, май, июнь, июль). Для каждого среза рассчитывался его embedding. Затем векторные представления из предыдущего месяца добавлялись в качестве дополнительных признаков к вершинам из переводов обучающей выборки следующего месяца (см. рис. 6). После добавления векторных представлений к вершинам в переводах вычислялись близость между вершинами, а для этого использовались две функции – косинусная близость и скалярное произведение.
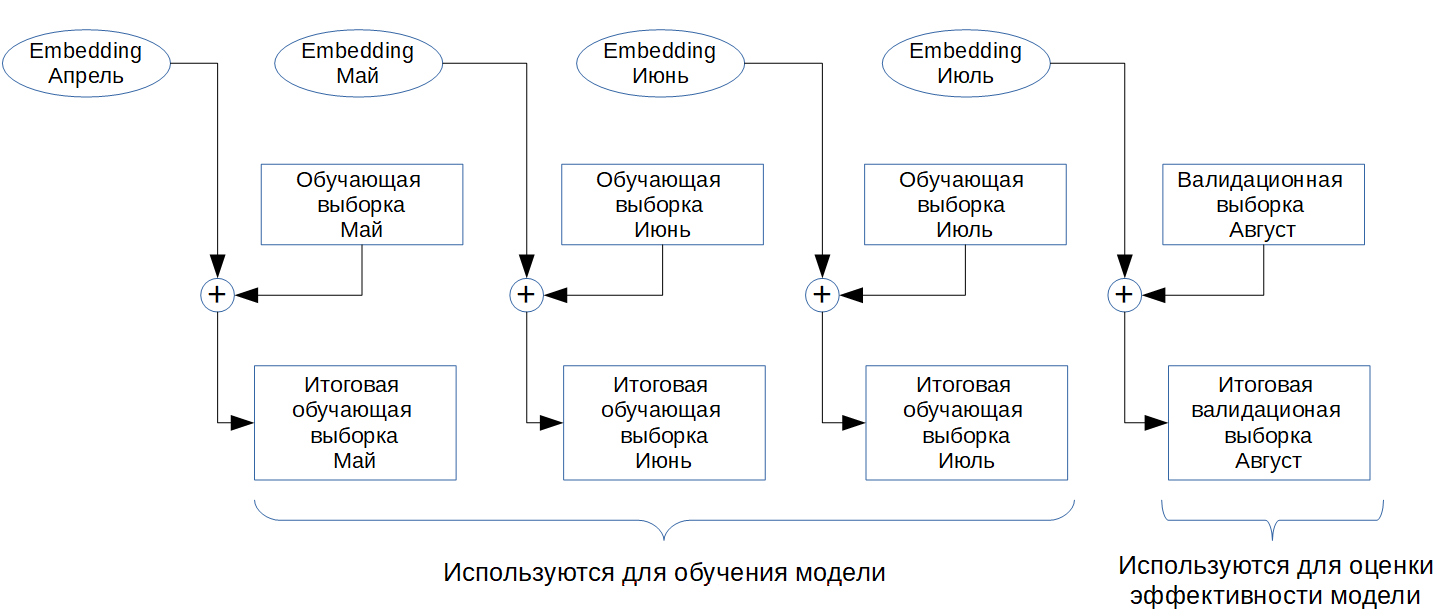
Рис. 6. Сопоставление embedding вершин на обучающую выборку
Доля покрытия переводов, когда и для отправителя, и для получателя нашлись соответствующие им embedding, при таком подходе составила около 80%. Непокрытые переводы возникают из-за появления новых клиентов/реквизитов, которых не было в графе. Для непокрытых переводов значения признаков embedding заполнялись NULL (алгоритмы градиентного бустинга умеют работать с отсутствующими значениями напрямую). Полученная таким образом обучающая выборка содержит в себе результаты GRL-моделей.
Результаты
Сравнив результаты моделей (без обогащения GRL-моделями и с обогащением) на валидационной отложенной по времени выборке, мы получили средний прирост Gini в 1,5–2%. В отдельных случаях прирост в точности работы модели при заданной полноте составлял 10–15% (см. рис. 7).
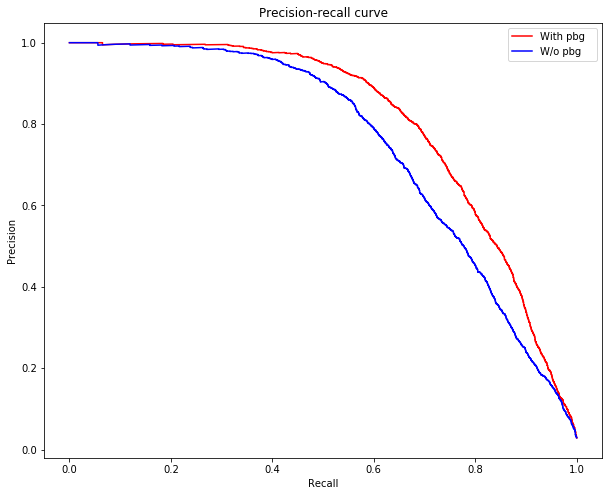
Рис. 7. График зависимости полноты и точности одной из моделей (синяя – без использования PBG, красная – с использованием PBG)
Мы также рассмотрели, какие из добавленных GRL-признаков по результатам отбора попали в финальную модель и на каких позициях. Оказалось, что сами по себе embedding вершины не информативны для модели выявления мошеннических транзакций (не прошли отбор признаков), но близости между вершинами, участвующими в транзакциях, вошли в пять наиболее значимых признаков моделей. И это при том, что в модели и так в явном виде присутствуют признаки, описывающие предыдущие взаимодействия между отправителем и получателем (число операций, длительность связи).
Разработанный подход может быть использован в real-time-моделях, потому что embedding рассчитываются заранее, а для скоринга транзакции на потоке дополнительно нужно по участвующим в транзакции вершинам найти соответствующие им embedding, а также рассчитать скалярное произведение и косинусную меру между найденными векторами. Все это при использовании inmemory-базы данных может быть выполнено очень быстро и не влиять на SLA моделей/фрод-мониторинг.
Выводы и перспективы развития
Полученные результаты показывают, что применение методов Graph Representation Learning в задачах противодействия мошенничеству дает существенный прирост эффективности, и это даже при условии, что базовые графовые эвристики использовались в моделях фродмониторинга. Если графовые данные не используются, то эффект от GRL-методов будет еще сильнее. При этом существующие инструменты Оpen Source уже достигли той степени зрелости, когда при минимальных доработках они позволяют строить эмбеддинги для очень больших графов (сотни миллионов вершин и миллиарды ребер). Соответственно, для внедрения подобных технологий требуются минимальные затраты вычислительных и временных ресурсов.
Сейчас мы проводим миграцию разработанного решения для промышленной эксплуатации и регулярного расчета embedding и по результатам обновим процессы обучения и сами модели фродмониторинга дополнительными GRL-признаками. У нас также в планах после вывода решения в промышленную эксплуатацию провести еще серию экспериментов в разных направлениях:
- попробовать другие размерности embedding, функций потерь и мер близости, доступных в PBG;
- при построении графа учитывать не только транзакционные, но и иные типы связей, а также проводить фильтрацию по ребрам/учитывать суммы как дополнительные веса ребер;
- воспользоваться пока экспериментальной функцией PBG, которая позволяет к вершинам добавить описывающие их векторы (например, возраст, оборот и пр.), то есть использовать решение уже в supervised-виде.
Вероятно, в результате будут найдены параметры, которые дадут еще больший положительный эффект для моделей. Кроме того, мы также исследуем применимость уже полученных embedding и для других задач противодействия мошенничеству. Например, используя эту информацию, можно провести кластеризацию клиентов, отметить вершины по уже известным мошенникам и определить кластеры с высокой долей их концентрации. Другие вершины в данном кластере могут быть еще не известными нам мошенниками.










